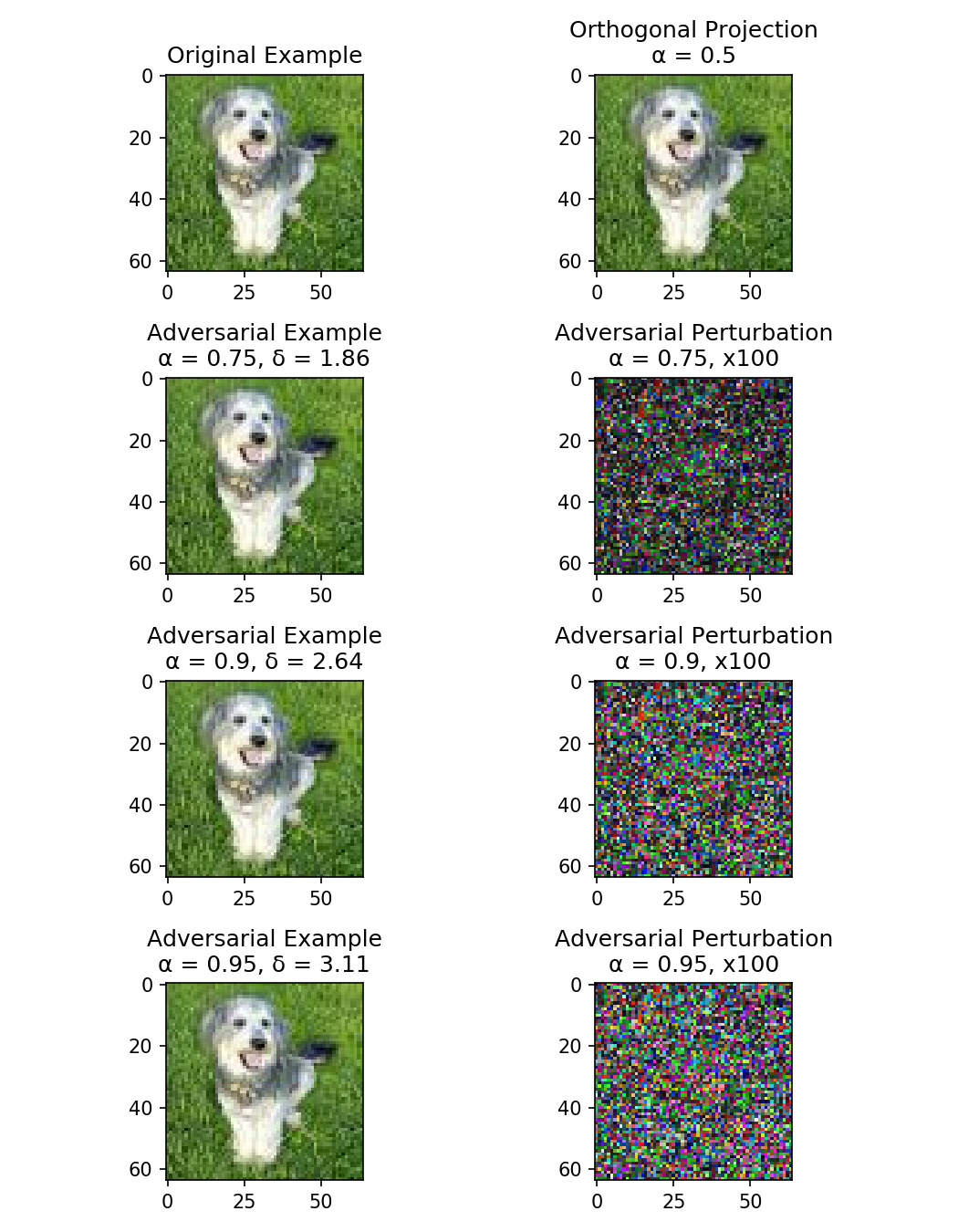
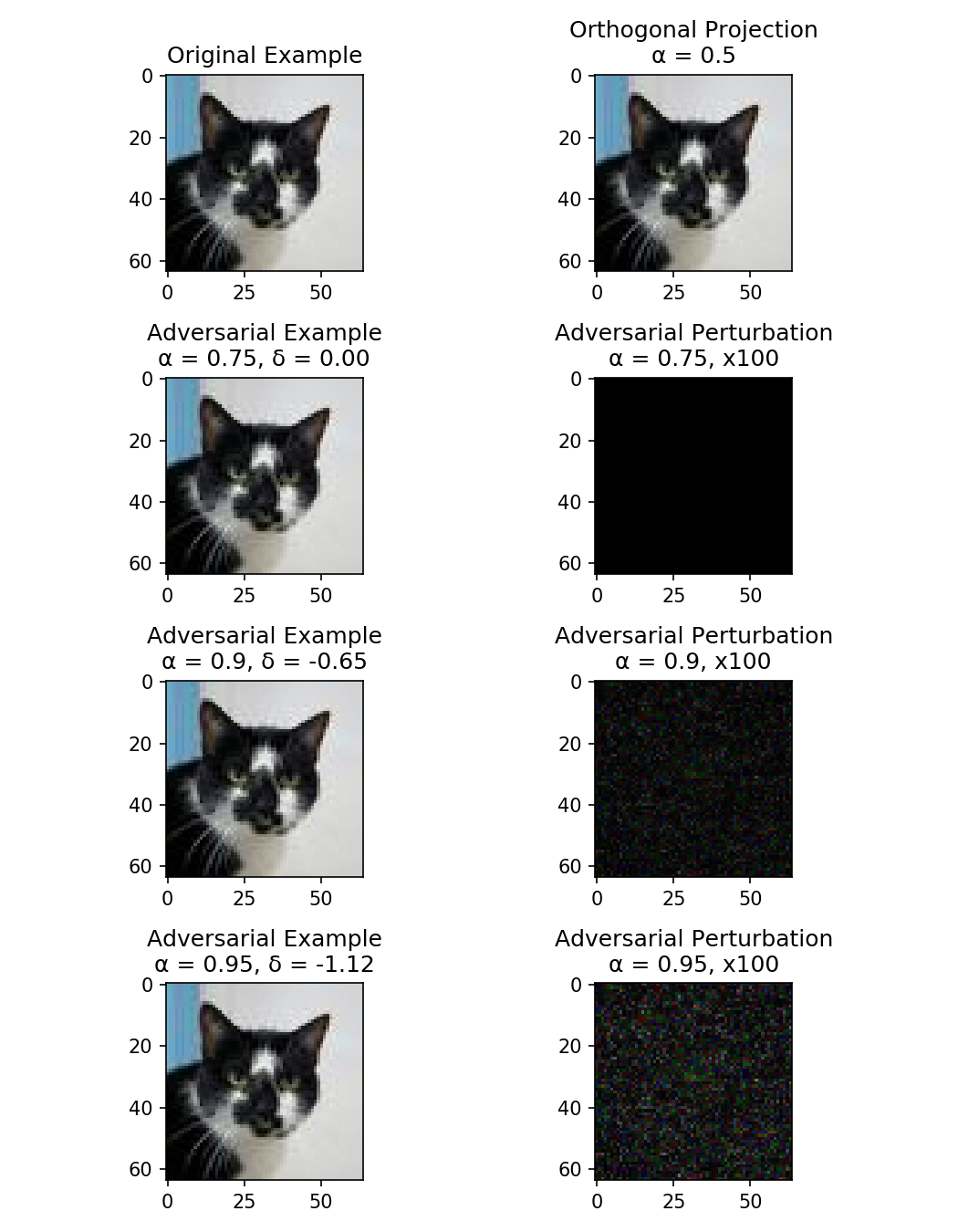
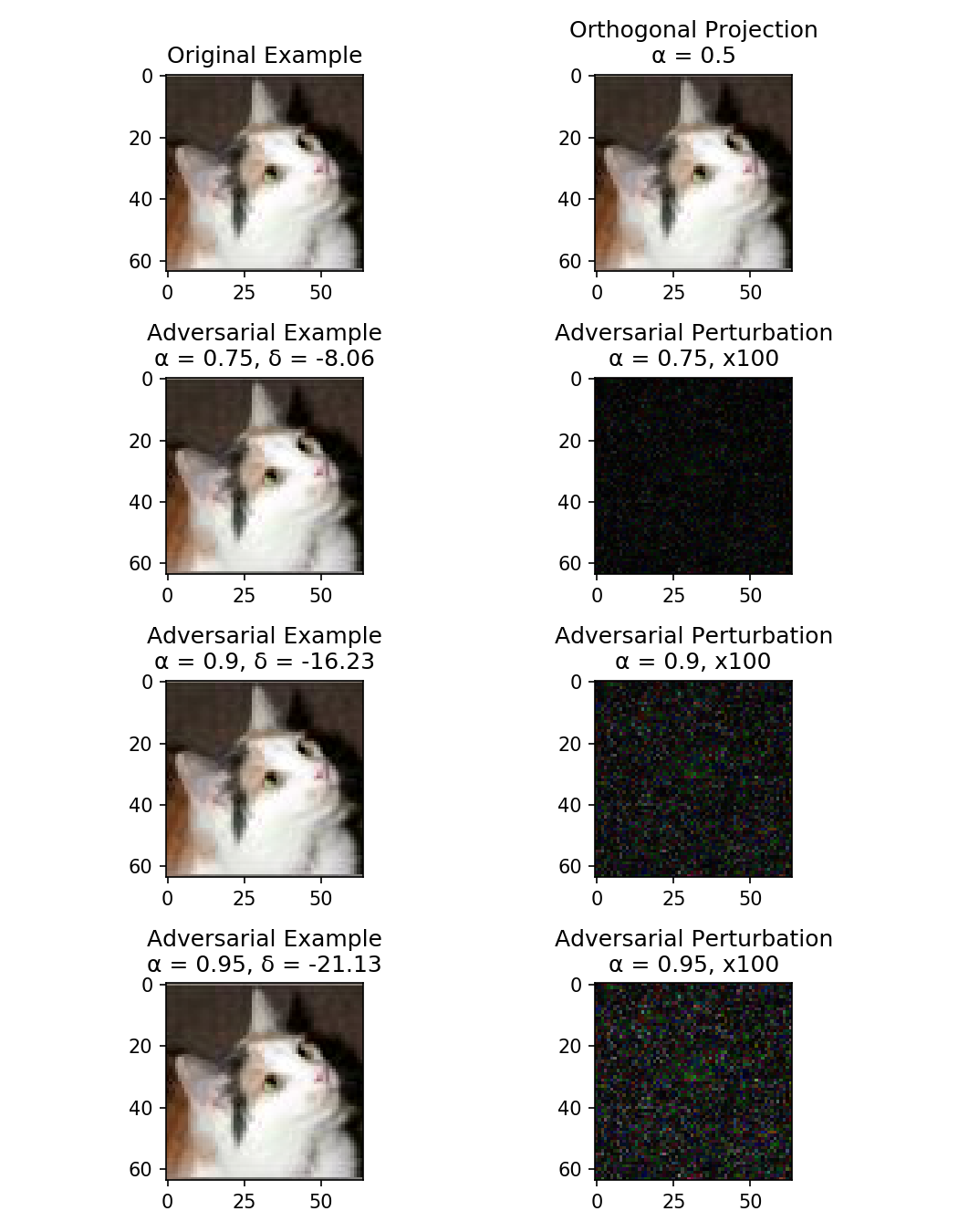
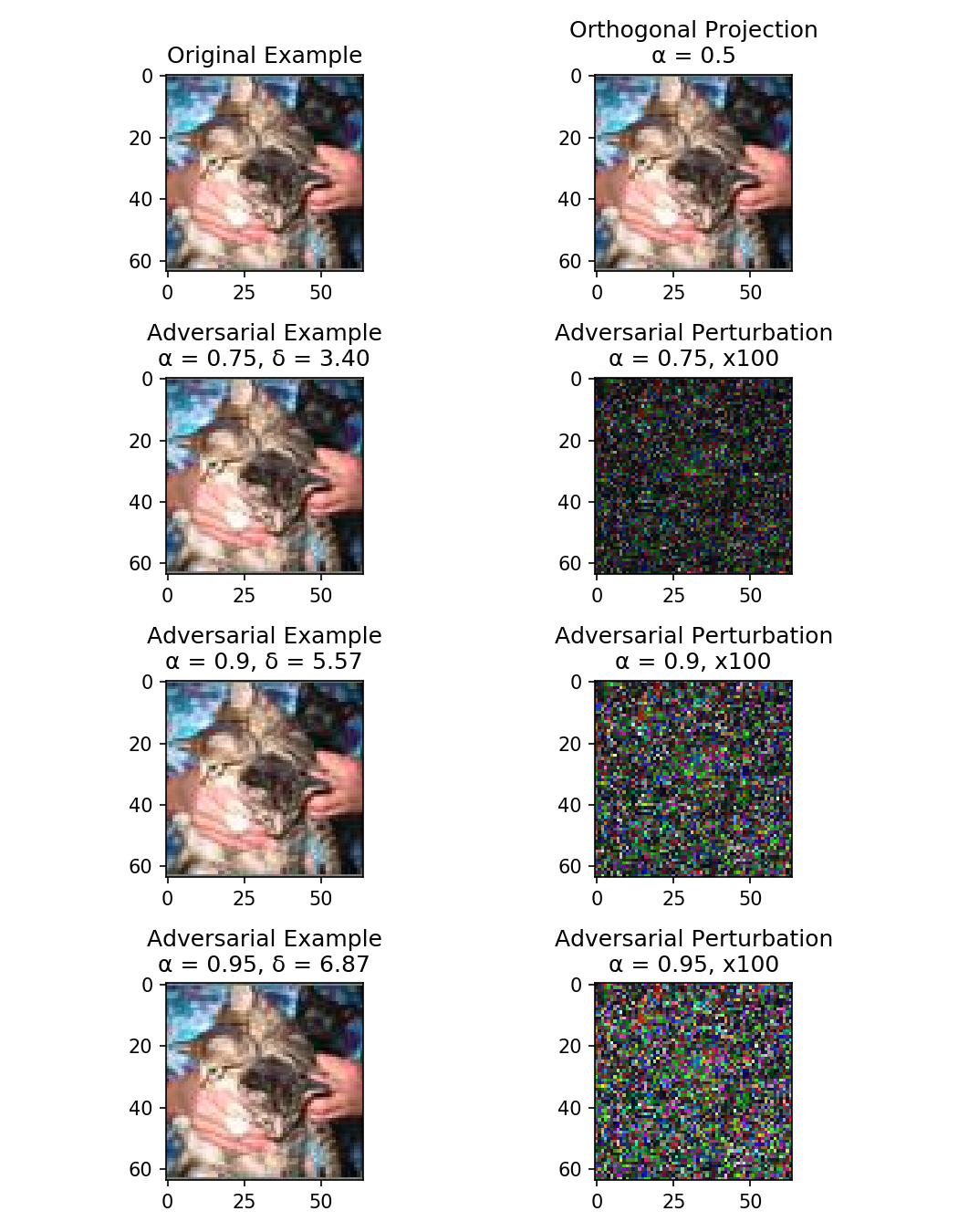
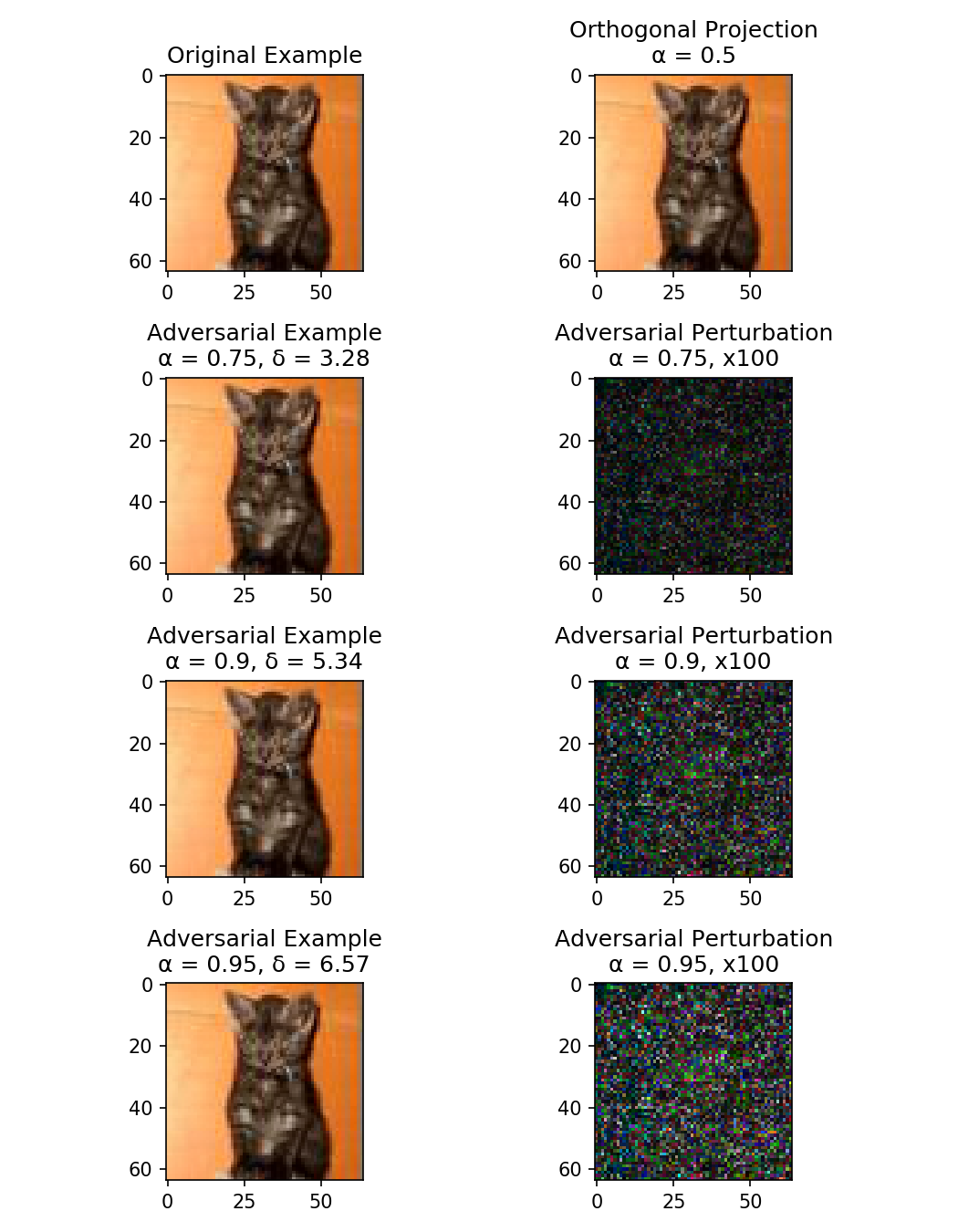
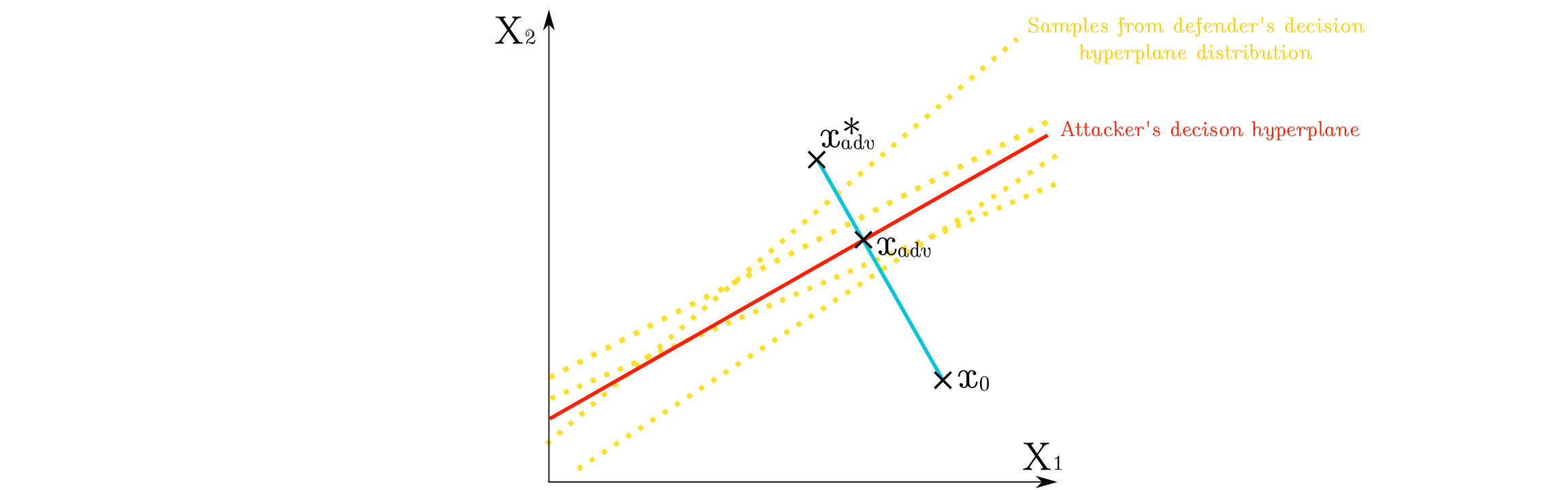
 Illustration of an adversarial example and some logistic regression decision boundaries
Illustration of an adversarial example and some logistic regression decision boundaries
Illustration of an adversarial example and some logistic regression decision boundaries
Illustration of an adversarial example and some logistic regression decision boundaries
Machine Learning models have been shown to be vulnerable to adversarial examples, ie. the manipulation of data by a attacker to defeat a defender's classifier at test time. We present a novel probabilistic definition of adversarial examples in perfect or limited knowledge setting using prior probability distributions on the defender's classifier. Using the asymptotic properties of the logistic regression, we derive a closed-form expression of the intensity of any adversarial perturbation, in order to achieve a given expected misclassification rate. This technique is relevant in a threat model of known model specifications and unknown training data. To our knowledge, this is the first method that allows an attacker to directly choose the probability of attack success. We evaluate our approach on two real-world datasets.
The manuscript can be downloaded from arXiv.