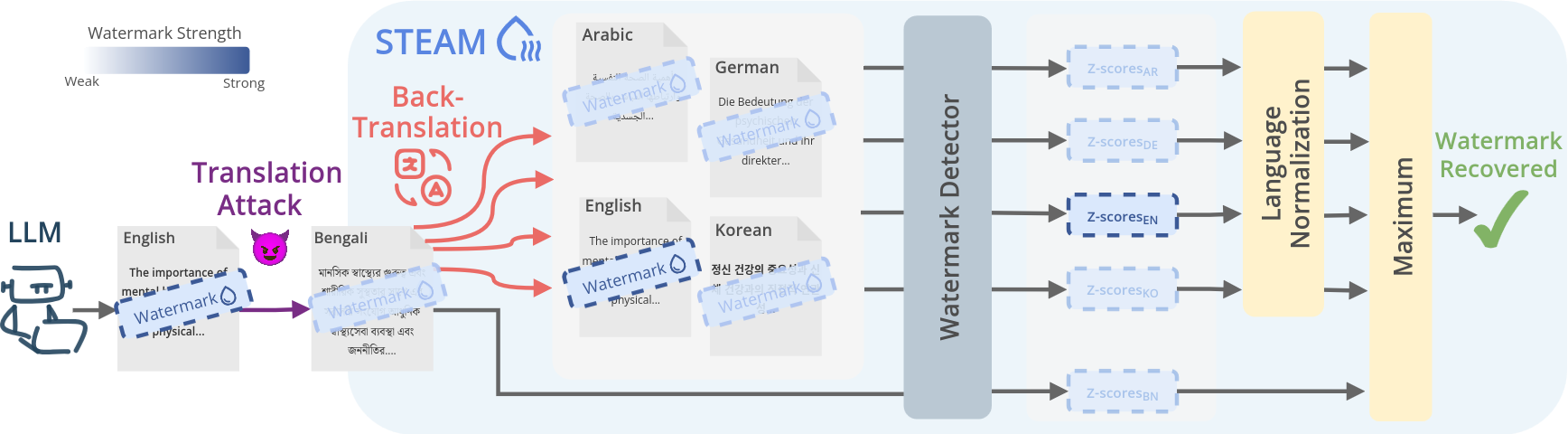
 Overview of STEAM.
Overview of STEAM.
Overview of STEAM.
Overview of STEAM.
Multilingual watermarking aims to make large language model (LLM) outputs traceable across languages, yet current methods still fall short. Despite claims of cross-lingual robustness, they are evaluated only on high-resource languages. We show that existing multilingual watermarking methods are not truly multilingual: they fail to remain robust under translation attacks in medium- and low-resource languages. We trace this failure to semantic clustering, which fails when the tokenizer vocabulary contains too few full-word tokens for a given language. To address this, we introduce STEAM, a detection method that uses Bayesian optimisation to search among 133 candidate languages for the back-translation that best recovers the watermark strength. It is compatible with any watermarking method, robust across different tokenizers and languages, non-invasive, and easily extendable to new languages. With average gains of +0.23 AUC and +37\%p TPR@1\%, STEAM provides a scalable approach toward fairer watermarking across the diversity of languages.
Previously titled “Is Multilingual LLM Watermarking Truly Multilingual? A Simple Back-Translation Solution”.
If you use our code or our method, kindly consider citing our paper:
@misc{mohamed2025steam,
title={Is Multilingual LLM Watermarking Truly Multilingual? Scaling Robustness to 100+ Languages via Back-Translation},
author={Asim Mohamed and Martin Gubri},
year={2025},
eprint={2510.18019},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2510.18019},
}