 Principles of semi-supervised learning
Principles of semi-supervised learning
Principles of semi-supervised learning
Principles of semi-supervised learning
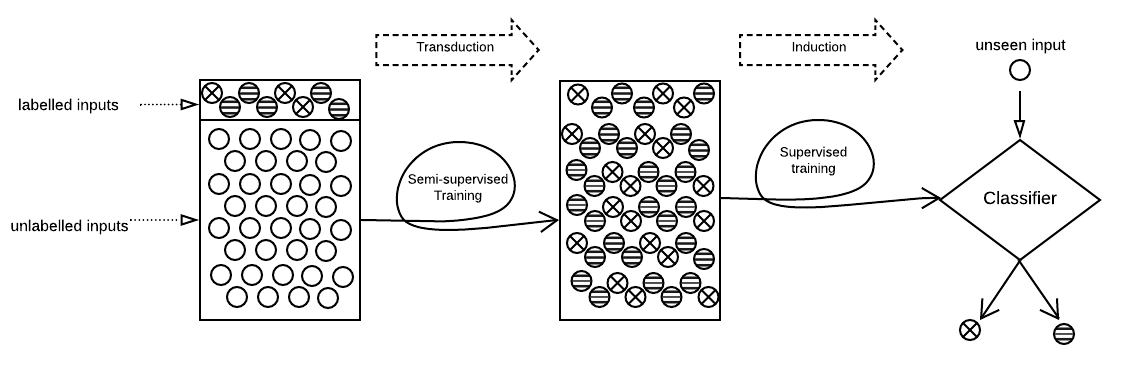
Semi-Supervised Learning (SSL) aims to maximize the benefits of learning from a limited amount of labelled data together with a vast amount of unlabelled data. Because they rely on the known labels to infer the unknown labels, SSL algorithms are sensitive to data quality. This makes it important to study the potential threats related to the labelled data, more specifically, label poisoning. However, data poisoning of SSL remains largely understudied. To fill this gap, we propose a novel data poisoning method which is both effective and efficient. Our method exploits mathematical properties of SSL to approximate the influence of labelled inputs onto unlabelled one, which allows the identification of the inputs that, if poisoned, would produce the highest number of incorrectly inferred labels. We evaluate our approach on three classification problems under 12 different experimental settings each. Compared to the state of the art, our influence-based attack produces an average increase of error rate 3 times higher, while being faster by multiple orders of magnitude. Moreover, our method can inform engineers of inputs that deserve investigation (relabelling them) before training the learning model. We show that relabelling one-third of the poisoned inputs (selected based on their influence) reduces the poisoning effect by 50%.