 Illustration of the relation between the training dynamics of the surrogate model, sharpness, and transferability.
Illustration of the relation between the training dynamics of the surrogate model, sharpness, and transferability.
Illustration of the relation between the training dynamics of the surrogate model, sharpness, and transferability.
Illustration of the relation between the training dynamics of the surrogate model, sharpness, and transferability.
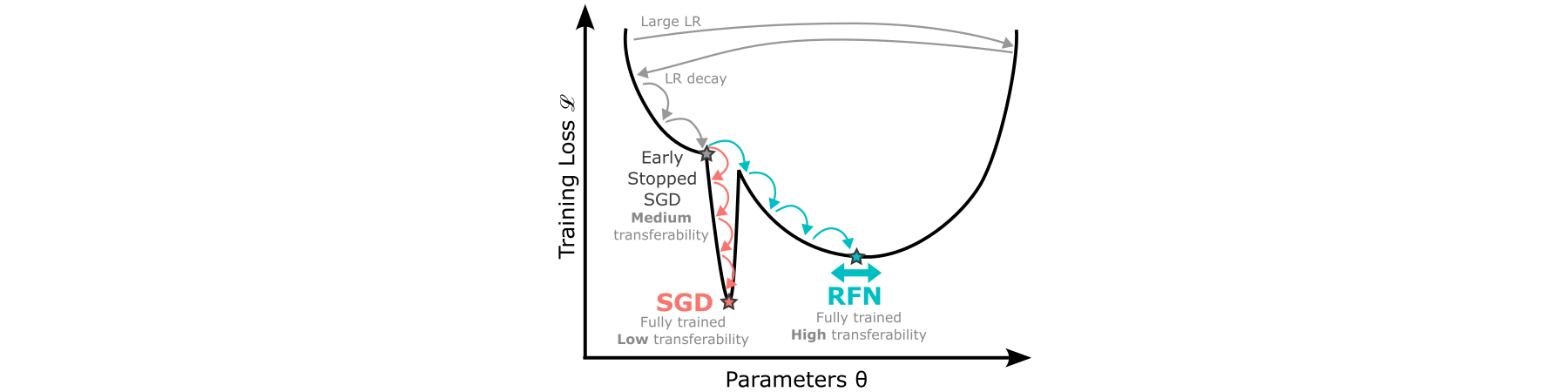
Transferability is the property of adversarial examples to be misclassified by other models than the surrogate model for which they were crafted. Previous research has shown that transferability is substantially increased when the training of the surrogate model has been early stopped. A common hypothesis to explain this is that the later training epochs are when models learn the non-robust features that adversarial attacks exploit. Hence, an early stopped model is more robust (hence, a better surrogate) than fully trained models. We demonstrate that the reasons why early stopping improves transferability lie in the side effects it has on the learning dynamics of the model. We first show that early stopping benefits transferability even on models learning from data with non-robust features. We then establish links between transferability and the exploration of the loss landscape in the parameter space, on which early stopping has an inherent effect. More precisely, we observe that transferability peaks when the learning rate decays, which is also the time at which the sharpness of the loss significantly drops. This leads us to propose RFN, a new approach for transferability that minimizes loss sharpness during training in order to maximize transferability. We show that by searching for large flat neighborhoods, RFN always improves over early stopping (by up to 47 points of transferability rate) and is competitive to (if not better than) strong state-of-the-art baselines.