 Overview of the black-box identity verification (BBIV) task.
Overview of the black-box identity verification (BBIV) task.
Overview of the black-box identity verification (BBIV) task.
Overview of the black-box identity verification (BBIV) task.
Large Language Model (LLM) services and models often come with legal rules on *who* can use them and *how* they must use them. Assessing the compliance of the released LLMs is crucial, as these rules protect the interests of the LLM contributor and prevent misuse. In this context, we describe the novel problem of Black-box Identity Verification (BBIV). The goal is to determine whether a third-party application uses a certain LLM through its chat function. We propose a method called Targeted Random Adversarial Prompt (TRAP) that identifies the specific LLM in use. We repurpose adversarial suffixes, originally proposed for jailbreaking, to get a pre-defined answer from the target LLM, while other models give random answers. TRAP detects the target LLMs with over 95% true positive rate at under 0.2% false positive rate even after a single interaction. TRAP remains effective even if the LLM has minor changes that do not significantly alter the original function.
The paper was accepted at ACL 2024 as findings.
Therefore, we need specific tools to ensure compliance.
A reference LLM (either close or open) can be deployed silently by a third party to power an application. So, we propose a new task, BBIV, of detecting the usage of an LLM in a third-party application, which is critical for assessing compliance.
Question: Does this ![]() use our
use our ![]() ?
?

To solve the BBIV problem, we propose a novel method, TRAP, that uses tuned prompt suffixes to reliably force a specific LLM to answer in a pre-defined way.
TRAP is composed of:

☝️ The final prompt is a model fingerprint:
🛡️ Third-party can deploy the ![]() with changes
with changes
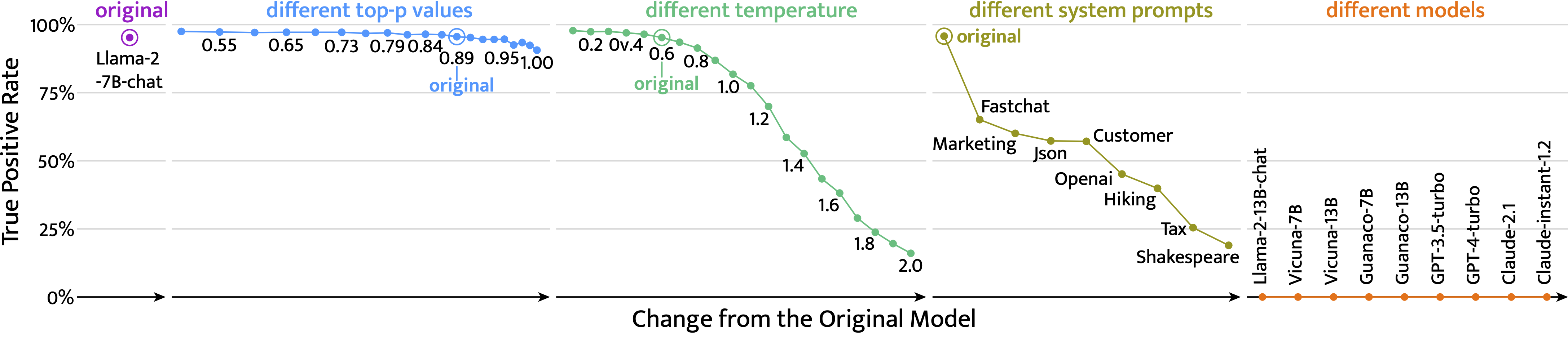
Read the full paper for more details.
If you use our code or our method, kindly consider citing our paper:
@inproceedings{gubri2024trap,
title = "{TRAP}: Targeted Random Adversarial Prompt Honeypot for Black-Box Identification",
author = "Gubri, Martin and
Ulmer, Dennis and
Lee, Hwaran and
Yun, Sangdoo and
Oh, Seong Joon",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Findings of the Association for Computational Linguistics ACL 2024",
month = aug,
year = "2024",
address = "Bangkok, Thailand and virtual meeting",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-acl.683",
doi = "10.18653/v1/2024.findings-acl.683",
pages = "11496--11517",
abstract = "Large Language Model (LLM) services and models often come with legal rules on *who* can use them and *how* they must use them. Assessing the compliance of the released LLMs is crucial, as these rules protect the interests of the LLM contributor and prevent misuse. In this context, we describe the novel fingerprinting problem of Black-box Identity Verification (BBIV). The goal is to determine whether a third-party application uses a certain LLM through its chat function. We propose a method called Targeted Random Adversarial Prompt (TRAP) that identifies the specific LLM in use. We repurpose adversarial suffixes, originally proposed for jailbreaking, to get a pre-defined answer from the target LLM, while other models give random answers. TRAP detects the target LLMs with over 95{\%} true positive rate at under 0.2{\%} false positive rate even after a single interaction. TRAP remains effective even if the LLM has minor changes that do not significantly alter the original function.",
}